It’s 2023 and WebAssembly is Still Not Ready. Or is It?

A couple of weeks back I was discussing the concept and “mental model” of WebAssembly with a colleague and friend of mine at Anyline GmbH, where we create a lot of impressive stuff in the domain of mobile scanning and machine learning. (Or, and by the way, we are hiring).
This conversation threw me to 2018, even before the pandemic, when I presented a talk at a local JS meetup about WebAssembly and how it can help us with creating new projects. At that time, I believed it to be a great tool, especially because it brought a lot of performance improvements. Somewhere in the 5–10x ballpark for a naive C/JS comparison.
During the last few years, however, a lot of things happened. Some of those things were good for web development: numerous improvements to the browsers’ engine performance, JS/TS getting into a “decent language” territory, and the ever-growing open-source community around the web stack.
A lot of people now ask:
It’s almost 2023 and WebAssembly has been around for over 5 years after its initial release in 2017. And yet, is it ready to be used in production environments and deliver the performance of C into JavaScript world?
Let’s see for our own.
For starters, let’s establish a benchmark. We want to measure the “performance in a vacuum”. This disqualifies a lot of UI interactions because the transition between WebAssembly and JavaScript adds some overhead which we, for now, want to avoid.
So, to give WebAssembly the best chances, let’s use Fourier transformations as it is a somewhat non-trivial, yet at the same time “pure” computational task. If you are unfamiliar with what it is, below is a fairly good explanation of the concept. But either way, for us it is a “somewhat computationally intensive task which is not a benign sorting”.
Test cases
Now, let’s get to the “fun part” — coding.
First of all, we’ll need a baseline with pure JavaScript:
export async function dft(x: number[]): [number[], number[]] {
const Xr = [];
const Xi = [];
let i, k, n = 0;
for(k = 0; k < x.length; k++) {
Xr[k] = 0;
Xi[k] = 0;
for (n = 0; n < x.length; n++) {
Xr[k] = (Xr[k] + x[n] * Math.cos(2 * Math.PI * k * n / x.length));
Xi[k] = (Xi[k] - x[n] * Math.sin(2 * Math.PI * k * n / x.length));
}
}
return [Xr, Xi];
}
The code is not a focus of this article, but let’s go over it quickly as we’ll be using adaptations of it for other languages as well. Here we implement the Discrete Fourier Transform, which is defined by the formula below:
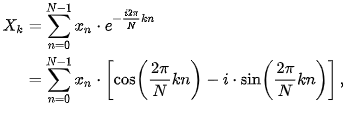
I specifically avoid using any language specific libraries which would provide implementation of complex numbers. This would add both complexity to the test code, as well as introduce performance variations based on each math library we’d use. Instead, I have used two separate arrays for real and imaginary parts of our X.
Reproducibility
In the following excerpts, I will only include minimal code samples to show the idea. As for the full repository with all the examined functions and benchmark methods, you can find it here.
Performance
Let’s get a performance baseline with our pure JavaScript approach:
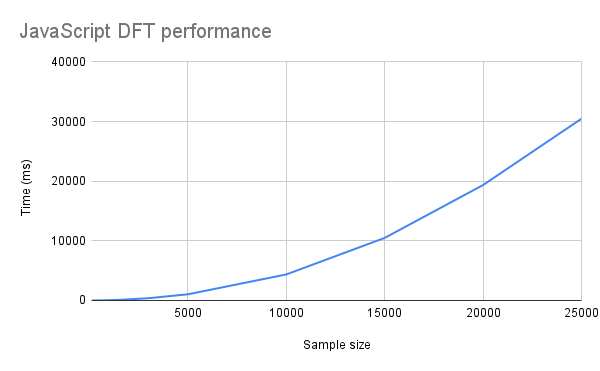
Here we see that our naive implementation of the Fourier transform indeed shows the properties of an O(n^2) algorithm.
Now, let’s see how better “fast” languages will fare against “slow”. Let me introduce our contenders:
- Go, because what can be wrong with a “new C”
- C/C++ itself, because it will never go away with the amount of legacy it has
I thought about adding Rust and Python to this comparison, but essentially the results were almost identical, so we’ll stick to the smallest subset for now.
Go
Golang’s implementation of DFT is almost identical to the JS one. The only important difference being that we need to somehow copy the array from the JavaScript’s memory into the heap space accessible to the Go code.
We are doing this by firstly calling CopyBytesToGo() which will move the input from “JS-space” into the slice of type []byte. Then, in the js_buffer_to_float64_slice function we transform this byte slice into a bunch of floats, which are the actual input. The function is not important for us here, but you can take a look in the repo: .
func DFT_naive(this js.Value, args []js.Value) interface{} {
input_array := make([]byte, args[0].Get("byteLength").Int())
js.CopyBytesToGo(input_array, args[0])
dft_points := js_buffer_to_float64_slice(input_array)
real := make([]float64, len(dft_points))
imag := make([]float64, len(dft_points))
arg := -2.0 * math.Pi / float64(len(dft_points))
for k := 0; k < len(dft_points); k++ {
r, i := 0.0, 0.0
for n := 0; n < len(dft_points); n++ {
r += dft_points[n] * math.Cos(arg*float64(n)*float64(k))
i += dft_points[n] * math.Sin(arg*float64(n)*float64(k))
}
real[k], imag[k] = r, i
}
return 0
}
C
As for the C implementation, we don’t need the machinery we used in Go to copy the data onto our functions heap written into it. All we should do is just accept a pointer to the first element of the array, and then iterate over it.
int calculateDFT(int len, int *points)
{
float Xr[len];
float Xi[len];
int i, k, n = 0;
for (k = 0; k < len; k++)
{
Xr[k] = 0;
Xi[k] = 0;
for (n = 0; n < len; n++)
{
Xr[k] = (Xr[k] + points[n] * cos(2 * M_PI * k * n / len));
Xi[k] = (Xi[k] - points[n] * sin(2 * M_PI * k * n / len));
}
printf("(%f) + j(%f)n", Xr[k], Xi[k]);
}
return 0;
}
Now, how do these two compare to JavaScript?
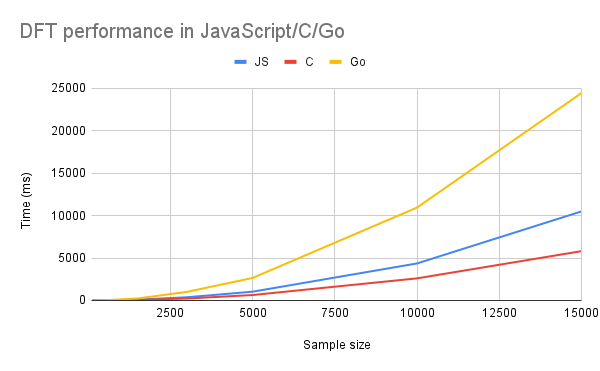
We can see some speed-up in the C implementation, but definitely not too dramatic. Moreover, for the Golang, the performance is actually way worse. That is probably because of the overhead added by the []byte->[]float64 conversion is done in quite a terrible way. But even for C code, the performance difference hovers around 50% between C and JavaScript:
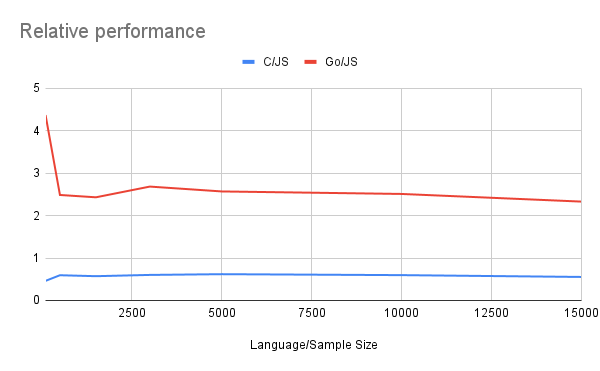
Is getting your application twice as fast worth re-writing all the “heavy pieces” in the new language, introducing it into your tech stack, spending time and money on hiring, and so on?
Sometimes, the answer actually will be “yes”, but almost certainly, this is not the most widespread use case. Indeed, spending thousands and thousands of dollars and hours, during which you could be building the product itself is rarely argued for. And if you know that it is your case, chances are, you already have good reasons and statistics to back them up.
This is exactly the argument a lot of people throw at somebody who dares to say: “WebAssembly is a nice piece of technology, we could benefit from using it”.
What they miss though is a huge amount of already existing code in C/C++, Go, Rust, and even Python. The best code is the code that does not exist. And here the best way to “write” it — is to reuse tooling from another ecosystem. Especially, if you already have some parts of your system written in it.
And when you can not only save half a year of development time but also get a 30–40% performance boost — I believe it to be “the best of both worlds” scenario.
As for the example we had today, I challenge you to implement a Fast-Fourier Transform (or use an existing one, like this) to see that language doesn’t win performance races, algorithms on the other hand — do!