Introduction to the OpenMP with C++ and some integrals approximation
Ever wondered how all those high performance servers work? How can we process huge amount of data on some computational heavy algorithm? Usually there are two approaches. You can split the task between several independent instances of the app. Basically, that’s what map-reduce approach usually does and to some degree can be implemented via microservices paradigm.

However today we will focus on another way. You can use more powerful machine and design your app so that single instance of it could use all the the available resources. It simplifies development as you don’t care about network interactions. Also you don’t have performance overheads for the infrastructure.
Standard C++ multi-threading is cool. Its fast and works well with numerous tasks. For example, what could be better for hello world apps on C++ multi-threading? But when it comes for some real world apps they usually take much time for implementation and testing. And thats when OpenMP enters the game.

… a folk definition of insanity is to do the same thing over and over again and to expect the results to be different. By this definition, we in fact require that programmers of multithreaded systems be insane. Were they sane, they could not understand their programs.
Edward A. Lee
OpenMP is a set of compilers directives, library procedures and environment variables which was developed for creating multi-threading apps for systems with shared memory (SMP computers) in 1997. This tool was initially designed for Fortan and later C and C++ were included as well. Nowadays, OpenMP is supported by the most popular C/C++ compilers: gcc, icc, PGI compiler. (Notice, that OpenMP isnt any kind of library in typical sense of that word. It doesn`t affect the output binary file directly.)
It`s important to understand that OpenMP works just on compilation time — it converts preprocessor directives to native Fortran/C/C++ code which is then compiled to executable. This allows the OpenMP to provide kind of “user friendly” interface without loosing performance. In the best case, of course.
So, lets finally take a closer look at this probably useful tool and start writing some code! The first example will be pretty simple, lets just say ethernal “Hello world” from multiple thread.
#include <iostream>
int main()
{
#pragma omp parallel
{
std::cout << "Hello World" << std::endl;
}
return 0;
}
To build this code you need to add -fopenmp flag, so that the compilation command would look like the following: g++ main.c -fopenmp -o main , and run it. Surprize! Instead of several rows with “Hello World” in each we received something like this:
HelloHello
Hello
Hello
HelloHello
Hello
Hello
That happens because multpiple threads are trying to write into the same “variable” (std::cout) simultaneously that causes data jumbling. Such situations are called race conditions and more details on that can be found here.
By default, OpenMP runs as many threads as there`re separate execution units are available in your system. However, these values can be adjusted with the following method:
#include <iostream>
#include <omp.h>
#include <unistd.h>
#define THREAD_NUM 4
int main()
{
omp_set_thread_num(THREAD_NUM); // set number of threads in "parallel" blocks
#pragma omp parallel
{
usleep(5000 * omp_get_thread_num()); // do this to avoid race condition while printing
std::cout << "Number of available threads: " << omp_get_num_thread() << std::endl;
// each thread can also get its own number
std::cout << "Current thread number: " << omp_get_thread_num() << std::endl;
std::cout << "Hello, World!" << std::endl;
}
return 0;
}
And for this one, we will see the following output:
Number of available threads: 4
Current thread number: 0
Hello, World!
Number of available threads: 4
Current thread number: 1
Hello, World!
Number of available threads: 4
Current thread number: 2
Hello, World!
Number of available threads: 4
Current thread number: 3
Hello, World!
Now, when we have covered the most basic things, lets go to some more realistic situations. For example, take an array of integers and get square for each of them and store to another array. First of all, we`ll do this in usual single thread way:
#include <iostream>
#include <algorithm>
#define ARRAY_SIZE 100000000
#define ARRAY_VALUE 1231
int main()
{
int *arr = new int[ARRAY_SIZE];
std::fill_n(arr, ARRAY_SIZE, ARRAY_VALUE);
for(int i = 0; i < ARRAY_SIZE; i++)
{
// do some relatively long operation
arr[i] = arr[i] / arr[i] + arr[i] / 5 - 14;
}
return 0;
}
Lets compile (with -O0 flag to prevent filling the array with final values on compilation) and run our program. For measuring performance we`ll use simple “time” command.
time ./main
real: 0m0.902s
user: 0m0.864s
sys: 0m0.032s
Now lets add multithreading for that example. The most obvious and wrong way is to do something like:
#pragma omp parallel
{
for(int i = 0; i < ARRAY_SIZE; i++)
{
arr[i] = arr[i] / arr[i] + arr[i] / 5 - 14;
}
}
Unfortunately, that doesn`t work. Actually, we will do loop operations in all available threads for the same value of i. Fortunately, all we need to fix that is to surround the loop with our calculations with another omp block:
#pragma omp parallel
{
#pragma omp for
{
for(int i = 0; i < ARRAY_SIZE; i++)
{
arr[i] = arr[i] / arr[i] + arr[i] / 5 - 14;
}
}
}
Also, this code can be written as following because we can group different blocks:
#pragma omp parallel for
for(int i = 0; i < ARRAY_SIZE; i++)
{
arr[i] = arr[i] / arr[i] + arr[i] / 5 - 14;
}
So, the full code of the our OpenMP program is:
#include <iostream>
#include <algorithm>
#include <omp.h>
#define ARRAY_SIZE 100000000
#define ARRAY_VALUE 1231
int main()
{
omp_set_num_threads(4);
int *arr = new int[ARRAY_SIZE];
std::fill_n(arr, ARRAY_SIZE, ARRAY_VALUE);
#pragma omp parallel for
for(int i = 0; i < ARRAY_SIZE; i++)
{
arr[i] = arr[i] / arr[i] + arr[i] / 5 - 14;
}
return 0;
}
And after running our simple benchmark we get following results:
time ./main
real: 0m0.430s
user: 0m0.980s
sys: 0m0.040s
As you can see, the total processor time consumed by the program increased. That is because creating threads and switching between them also requires some resources. However, this time (and processor instructions respectively) “splits” between different execution units and as a result the real time the program worked has decreased by half. And this improvement was achieved for algorithm in which the only operation for each thread was addition of 2 divisions, which should not take more than ~ 1000 CPU clock cycles.
Finally, we will do quite real life thing — numerical approximation of the integral of the 2-variables function. This is so called de Jong function.
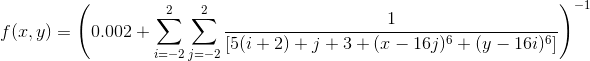
First of all, we need to define this function itself. As for now, we don`t need it to be multithread or optimal, so the following implementation is OK for us.
double f(double x, double y)
{
double result = 0.002;
for(int i = -2; i <= 2; i++)
{
for(int j = -2; j<=2; j++)
{
double temp_res = 1 / (5*(i+2) + j + 3 + std::pow(x - 16*j, 6) + std::pow(y - 16*i, 6));
result += std::abs(temp_res);
}
}
return 1.0 / result;
}
And the main integrating function, which will do the most of the job. Now, lets marks fragments which can be quite easily paralleled.
double integrate(double x_from, double x_to, double y_from, double y_to, double precision){
int threads = omp_get_max_threads();
double xInterval = std::abs((x_from - x_to)) / (double)threads;
double result = 0;
#pragma omp parallel for
for(int i = 0; i < threads; i++){
double x_from_val = i * xInterval;
double x_to_val = (i + 1) * xInterval;
double y_from_val = y_from; // we create these variables, to avoid race condtions between different threads and moreover braking the data. Now, this is a thread-local variable.
double y_to_val = y_to;
double sum = 0;
while(x_from_val <= x_to_val)
{
double y0 = y_from_val;
while(y0 <= y_to_val) {
sum += f1((2 * x_from_val + precision) / 2, (2 * y0 + precision) / 2) * precision * precision;
y0 += precision;
}
x_from_val += precision;
}
#pragma omp critical
result += sum;
}
return result;
}
So, we have split our whole input space into such number of subspaces as many threads we can create. And now lets test it! And after that a single thread version of this code (simply comment #pragma lines).
time ./mainThreads (4 threads) time ./mainSingleThread
real: 0m0.030s real: 0m0.101s
user: 0m0.132s user: 0m0.100s
sys: 0m0.008s sys: 0m0.000s
As we can see, OpenMP allows to simplify using of multi-threading in C/C++ and save you a lot of time. And you should not care about the locks and race conditions besides some quite straight tools.
So, is it a kind of silver bullet which can do just everything in multi-threading domain? Unfortunately, theres no silver bullets. And business systems are slow, and legacy code is everywhere. OpenMP cant deal with computations which rely on previous chains of computation chain. So, if you were going to calculate factorials or something like that, it is a bad idea. However, if you want to do something that you could do with usual C/C++ threads but don`t want to spend your time for playing with some low level stuff which will not give you any benefits, OpenMP might be just a right tool for you.
If you want to read more about OpenMP, these links are quite cool: