Can we use local LLM to enhance traditional chatbot output on a budget?
Introduction
We all know that large LLMs can be great for many applications, but they also bring unique risks of being very “confident liars”. Additionally, it takes an incredible amount of computing power to operate and the costs do add up. On the other end of the spectrum, there is a whole world of open-source LLMs that can be run locally (or on-prem) often on a fraction of resources.

Even though these smaller LLMs often lack the performance and capabilities of their well-known counterparts like ChatGPT, Gemini, and others, I wanted to test how we can use them locally to enhance user experience with a more “alive” presentation of some factual information.
As the simplest example, I am going to use the weather forecast because it is the most straightforward case of a “question → factual answer” scenario.
The goal for today’s exercise is to create a Python wrapper around one of the open-source LLMs. This package will take weather data as its input, do some “magic”, and return a text message with the weather information and some “personalized” flavor.
Baseline
As a first baseline, I have created a super minimalistic setup that prints the weather provided. Nothing fancy, just the “parameter = value” type of output. For most cases, it’s good enough and can be used either directly or with some processing as an output for our bot.
As one would expect, the output is nothing fancy but it does its job:

But we (maybe) can do better, can’t we?
Choosing the model
There are a lot of free and open models nowadays. As of recently the OpenHermes Mistral 7B was quite decent in my experiments, so I have decided to start with it.
First attempts
I am using the public Inference API by HuggingFace. Mainly, because it is simple and does the trick for this one-evening endeavor. Of course, for the “production” usage one would want to run the model either on-prem or in a private cloud, but for the initial testing, it seems to be good enough.
For now, we extend our “message generating” class with an API call to HuggingFace like this:
In this iteration, I am not too concerned about tinkering with the prompt and only want to get a reasonable enough message output. That we have achieved. For weather conditions of 45 degrees Celsius, 50% humidity, no chance of rain, and 5 kph wind, we get the following outputs from the Mistral 0.2 model:
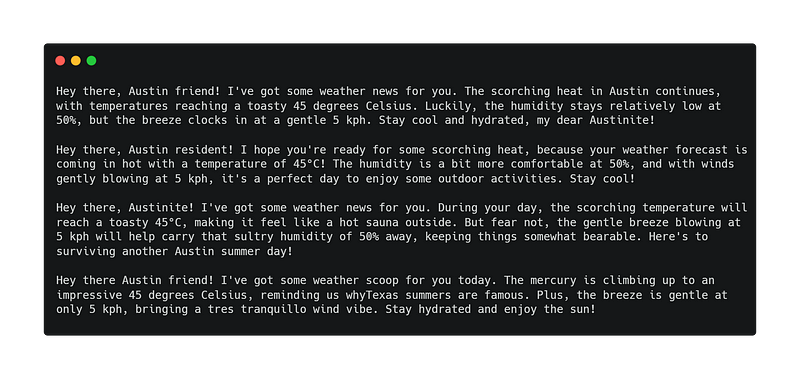
Not perfect, but I’d say a good enough first result without any major tuning, or even time investment.
Can we prevent it from lying?
One thing that modern language models are infamous for is either outright lying or complying with prompts just partially. When toying around with the prompts I had several occasions when the model would not mention all of the parameters for seemingly random reasons.
The simplest option is to always verify that the model’s output contains all the “numbers” (i.e. temperature, wind, and so on) from our weather object. Then we will simply regenerate the output until the model includes all the data points we need. This approach seems quite similar to unit testing and I think it’s quite useful, especially in cases when we have a set of “hard facts” and need to only generate additional “flavoring” around them.
For this exercise I have implemented a very dumb approach which nonetheless is sufficient to sieve out the most obvious failed attempts:
def __validate_weather_message(self, weather: WeatherInfo, message: str):
return ((str(weather.temperature) in message)
and (str(weather.wind_speed) in message)
and (str(weather.wind_speed) in message))
def __prepare_weather_message(self, weather: WeatherInfo, location: str, retries: int = 5):
message = self.__get_llm_output(weather, location)
if not self.__validate_weather_message(weather, message) and retries > 0:
print('Will retry weather generation')
return self.__prepare_weather_message(weather, location, retries - 1)
return message
def get_user_message(self, weather: WeatherInfo) -> str:
return self.__prepare_weather_message(weather, "Austin, Texas")p
Crude and overly simplistic, but hopefully will be sufficient to get us going. Indeed, we are getting quite good outputs here:
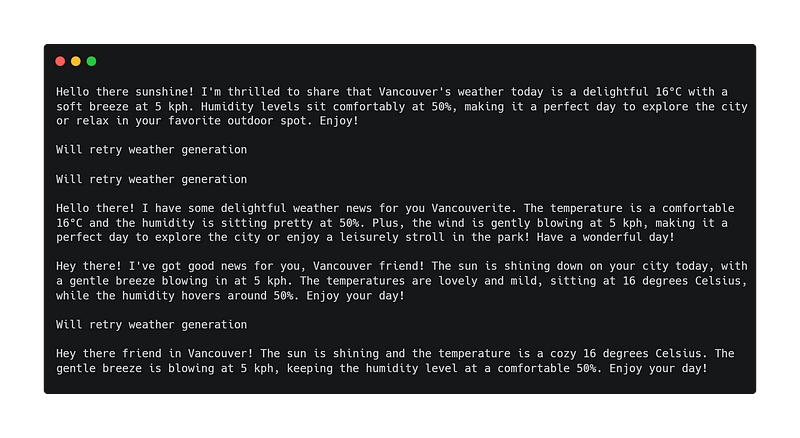
Wrapping it all up
So, after a couple of hours playing with free text generation models, I would say that even without paying the steep price for OpenAI or competitors’ API access one can get quite some benefits of modern LLMs. What we’ve created today is not the most sophisticated or powerful solution, but even at this point adds enough value to at least consider using it.
All in all, it looks like we can confidently use smaller and/or free and open large language models to enhance our otherwise deterministic applications. On top of that, it is now possible and feasible to use CPU-only environments for these “occasional” computations. More likely though, you’d still need a dedicated node/cluster to run the “LLM-ed” part of the application.
With that being said, get out there and have fun!